今天我們要來介紹OpenAI在2017發表多智能體的經典之作 Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments, 接著後面會再大家跑一下程式碼。
在許多場景,例如像是智慧工廠,如果我們直接用Q-learing或者policy的演算法,去訓練多個agents,會造成收斂不穩定,因為環境一直受到其他智能體感擾的問題,以及在一些競爭的條件下,彼此的演算法也會陷入納什均衡的狀態,導致頻繁的變換。OpenAI推出MADDPG的的方法,以DDPG為基底,考慮了critic全局觀測,actor分散執行的應用,使得agents可以在合作與競爭的條件下,穩定的收斂到局部最佳解。
該研究提出三種方法,穩定多智能體的訓練
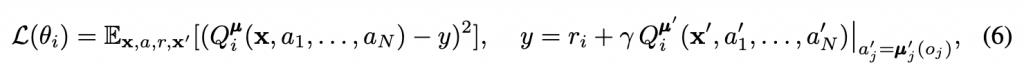
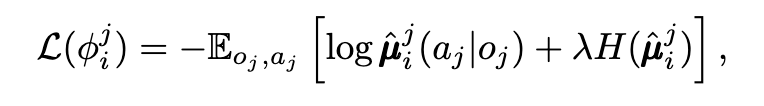
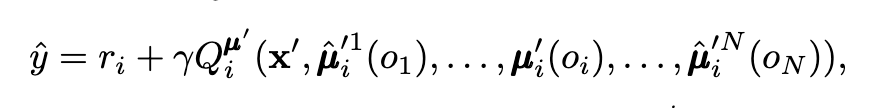
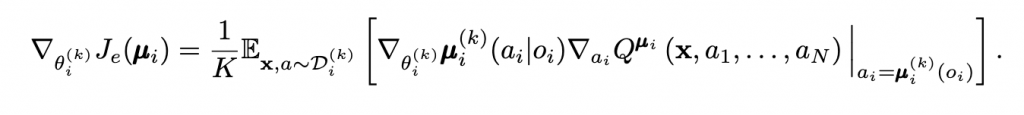
其實蠻純粹的,更多資訊量達到穩定性,不過也是挺好奇量與訓練穩定性的正相關如何,或是說agents做的事情,如果又更複雜的話,例如不是單純球球藉由距離去吃分,而是讓agents打一個RPG組隊遊戲的話,不過我相信這種複雜的題目,就需要更多工程的努力與理論的考驗了。

